The main new features already implemented for the version that will be shipped with KDE 4 are:
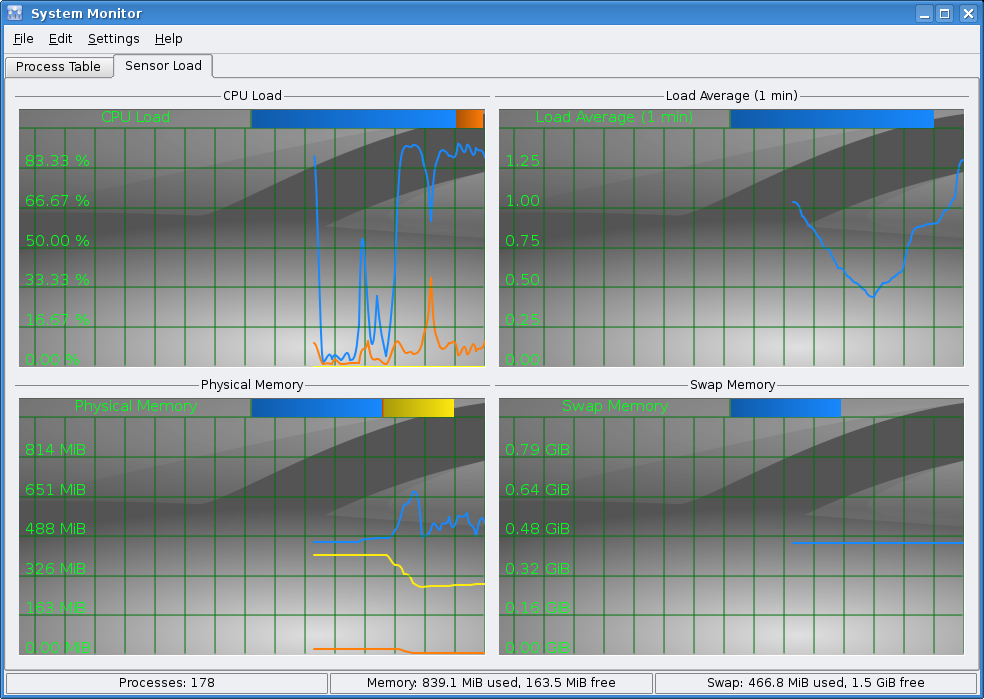
- The graphs are anti-aliased, with beautifully-smooth bezier curves connecting the points.
- SVG support for the graph plotter backgrounds.
- Units are shown within graphs, with nicer tooltips showing a key along with the current values.
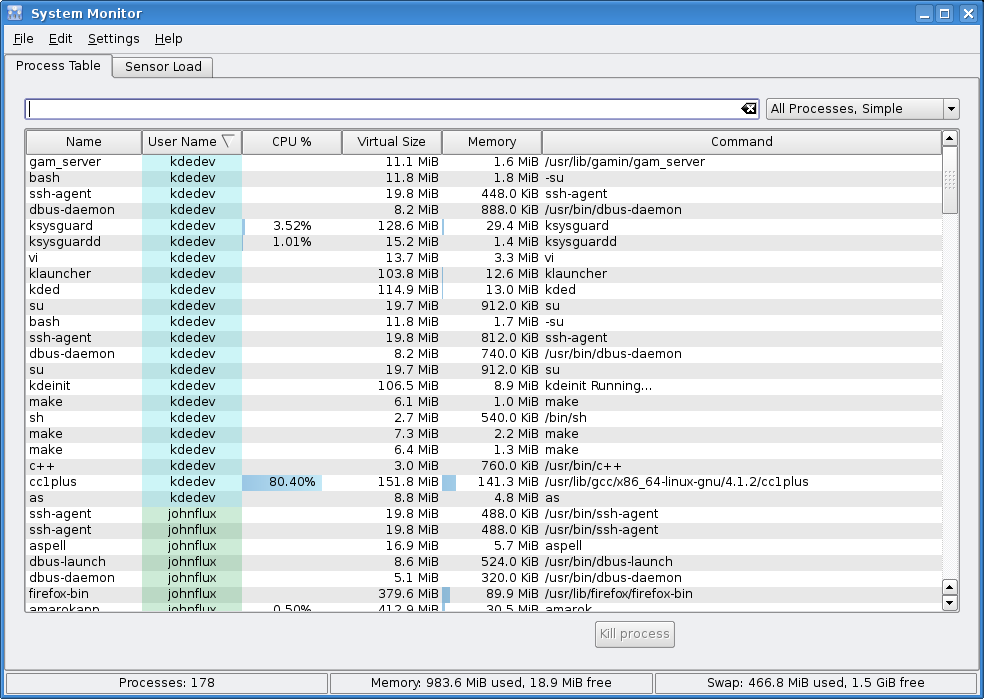
- The list of processes is greatly simplified, with the default sorting being by user 'type' first (own user, other users, system), and then by CPU usage.
- Subtle colors are used to enhance usability, using the Oxygen colors.
- A more complex process list shows information such as the amount of X-Server memory a process uses, and the window title of the application.
- A large amount of work has gone into performance, startup time and memory usage optimisation.
- A beautiful, semi-transparent gradiented progress bar is shown for the CPU percentage and memory usage, again also using the Oxygen colors.
- The list of processes running. This is the first thing you see when ksysguard is launched. It shows processes owned by the current user at the top, sub-sorted by the CPU usage. Every field for every process has a detailed tooltip with more information.
- The same list displayed as a Tree view.
- An experimental SVG background for the graph plotters. One idea is to have the background dark with a watermark changing for each graph. For example, a CPU watermark for the CPU chart. Note the anti-aliased rendering in this view. Artists, send in suggestions!
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}